告诉大语言模型(LLM)一个环境条件(比如附近有电话)会影响它的表现吗,即使大语言模型(LLM)显然没有电话?这个问题将这些看似毫不相关的研究联系起来,并构成了我的实验基础。
如果你的心智模型是 LLM 会记住所有输入并进行训练,那么你就会更容易认为那些声称他们已经禁用了这种能力的开发者可能没有说实话。如果你告诉你的人类朋友不要理会你误传给他们的一则有趣的小道消息,你很清楚他们是不会忘记的!
作者 | ROHIT KRISHNAN 译者 | 刘雅梦 策划 | Tina 在过去的几年里,每当我们遇到大语 […]
谷歌已将 Pulumi AI(一家使用人工智能聊天机器人生成基础设施的开发商)制作的不准确的基础设施即代码样本编入索引,这些烂菜谱已经出现在搜索结果的顶部。
我最近看到几篇文章,作者提到要求 LLM 以一定的概率或一定的百分比做某事。有一个特别的例子让我记忆犹新,但我已经失去了它的链接
清单的制定创建OWASP LLM申请前 10 名列表是一项艰巨的任务,它建立在由近 500 名专家和超过125 名积极贡献者组成的国际团队的集体专业知识的基础上。我们的贡献者来自不同的背景,包括人工智能公司、安全公司、ISV、云超大规模提供商、硬件提供商和学术界。
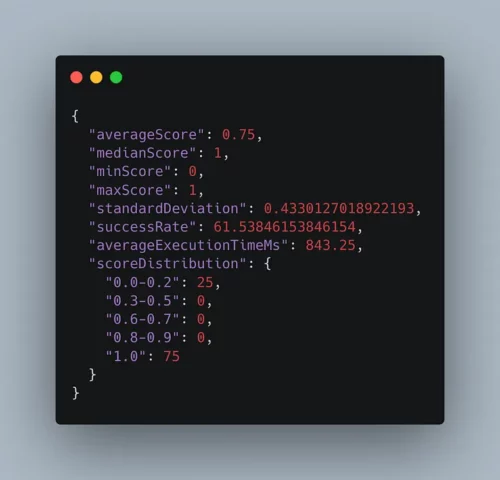
当要求人工智能在 1 到 100 之间选择一个数字时,会形成一个非常有趣的分布。选择 “42 “这个数字的权重很高。
想象一下,你提供一个 LLM《哈利-波特》里的一章,让它数一数 “巫师 “这个词被提到了多少次。GPT4、Claude 3 Opus、Gemini Ultra 和 Mixtral,但在这项任务中都失败了。
这种情况–陡峭的学习曲线问题–现在变得容易多了,这要归功于 LLM(Large Language Model,大型语言模型)。
完蛋了,程序员要大面积失业了。真的是这样吗?要回答这个问题,我们需要从全局来看问题,首先我们要搞清楚,LLM 对于软件研发,什么变了?什么没有变?
他们知道你手机上的全部应用程序
20 年前的 exe 现在仍然可以在 Windows 上运行,linux 呢?
自我感觉良好
战争故事:我调试过的最难的错误
在选择 Next.js 之前,您应该了解这些信息
非官方 Windows 7 Service Pack 2
进化中的 SCALA 语言
氧化 Ubuntu:默认采用 Rust 实用工具
我认识的最糟糕的程序员
初级开发人员的复仇