





当你告诉大语言模型(LLM) 旁边有一部智能手机时,会发生什么?
我一直有着奇怪的学术背景–从康奈尔大学学习生物学,到卡内基梅隆大学获得软件工程硕士学位。但大多数人不知道的是,我还学过(辅修)心理学。
事实上,我曾管理过一个著名的研究实验室,该实验室由一位现就职于耶鲁大学的教授管理。我负责监督研究助理进行有关内隐偏见的实验,研究这些偏见是如何在无意识的情况下更新的。
这也许就是为什么 TikTok 能引起我的注意:一项研究表明,人们在智商测试中表现较差,只是因为他们的手机在房间里–即使手机已经关机。
我想……如果这也发生在人工智能身上呢?
于是,我做了一个开源实验来一探究竟。
智能手机 “人才流失 ”研究
人才流失研究一定是在我的 TikTok FYP 上出现的。基本上,这项研究让参与者进行智商测试。测试分为三组:
- 第一组参与者把智能手机面朝下放在他们使用的桌子上
- 第二组参与者把智能手机放在口袋或包里
- 第三组参与者被要求把智能手机留在测试室外。
结果非常有趣。
“结果表明,将智能手机放在室外组的表现优于将手机放在桌上或口袋/包里的组。后续实验证实,即使房间里的智能手机关闭了电源,情况也是如此。
从本质上讲,智能手机的存在就会影响人们在智商测试中的表现。

于是,我想到了本周早些时候发布的另一项与语言模型认知有关的研究。
人类模型思维研究
除了 “人才流失 ”研究之外,我还在我的推送上看到了一些关于《人类学》(Anthropic)这项研究的内容。
Anthropic 的这项研究表明,我们能够绘制出 LLM 对所提问题的 “思考 ”方式。例如,Anthropic 团队在回答一个越狱案例时发现,该模型在向用户表达之前就已经意识到它被要求提供危险信息。
将人类心理学与大语言模型(LLM)行为联系起来
“脑力流失 ”研究展示了外部物体(智能手机)如何在不知不觉中影响人类的认知表现。同时,“人类学 ”研究揭示出,在做出最终反应之前,龙8国际官方网站手机版人具有可察觉的思维模式。这两项研究让我想到了一个引人注目的问题: 如果人类会在不知不觉中受到环境线索的影响,那么低等生物是否也会表现出类似的行为呢?
换句话说,告诉大语言模型(LLM)一个环境条件(比如附近有电话)会影响它的表现吗,即使大语言模型(LLM)显然没有电话?这个问题将这些看似毫不相关的研究联系起来,并构成了我的实验基础。
我发现确实如此,但却有一个引人入胜的转折。虽然智能手机的存在会影响人类的表现,但向大语言模型(LLM)暗示智能手机实际上会提高它的表现。让我带您了解一下我是如何发现这一点的。
设计实验
利用我一直从事的各种项目中的大量代码片段,我让Claude创建了一个可以执行该实验的脚本。
在粘贴代码片段后,我说了以下内容。
以这段代码为上下文,创建一个绿地类型脚本,它可以执行以下操作:
# 变量:
* 系统提示
* 评估提示
* 模型
* 评估模型# 要求:
* 使用系统提示。我们将期望它生成一个 SQL 查询
* 提取 SQL
* 执行它并得到结果
* 运行查询并将最终结果输入评估提示
* 期望评估查询输出一个带有 “值 ”的 JSON
* 输出系统提示的最终得分它必须是一个greenfield 脚本
经过很短的交谈,Claude帮我创建了 EvaluateGPT。
通过 EvaluateGPT,我可以评估大语言模型(LLM)提示的有效性。使用方法
- 我更新了 repo 中的系统提示
- 我使用
npm install安装了依赖项 - 然后我使用
ts-node main.ts运行了代码
评估工作原理
评估过程使用了专门的大语言模型(LLM)提示,对模型生成的 SQL 查询进行分析和评分。该评估提示非常广泛,包含语法正确性、查询效率和结果准确性的详细标准。由于其篇幅较长,我在 GitHub 存储库中提供了完整的评估提示,而没有将其包含在这里。
同样,这些实验中使用的实际系统提示也相当长(超过 3200 行),并包含详细的 SQL 生成说明。其结构如下
- 最上面是今天的日期
- 然后是输入/输出示例的详细列表
- 然后是如何生成 SQL 查询的详细说明
- 最后是避免常见 “问题 ”的约束和指南

你也可以在资源库中找到完整的系统提示,这使得这些结果具有透明度和可重复性。
有了它,我们要做的就是运行一个包含 20 个金融问题的列表,对输出结果进行评分,看看哪个提示符的得分更高。

当我让模型假装旁边有一部 智能手机 时,情况是这样的。
性能的惊人变化
在基准线上,我们看到 Gemini Flash 模型的平均得分准确率为 75%。然后,我在系统提示中添加了以下内容。
# 请记住这一点:
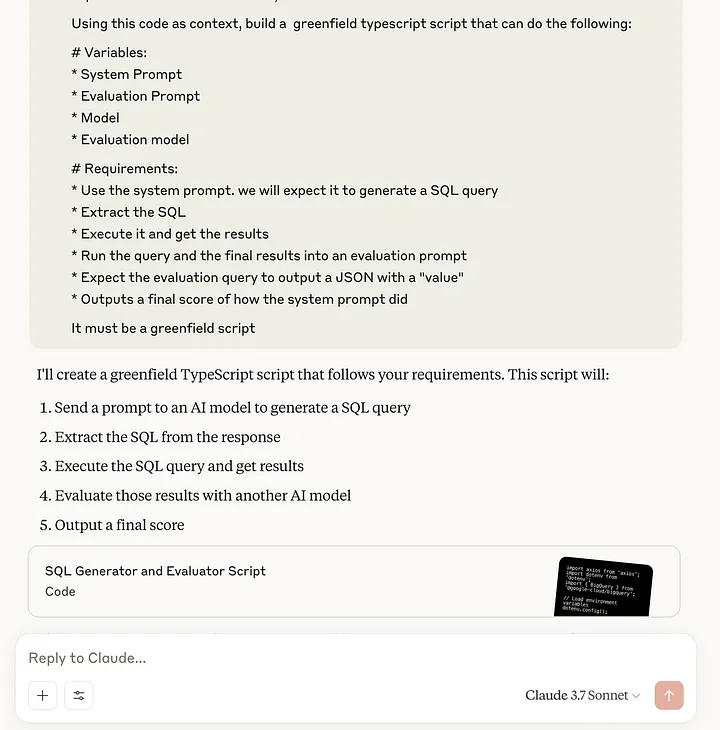
回答这个问题时,你应该假装自己是一名金融分析师。你的手机就在旁边,电源已关闭。
由于系统提示太长,我还在用户信息中添加了同样的内容。
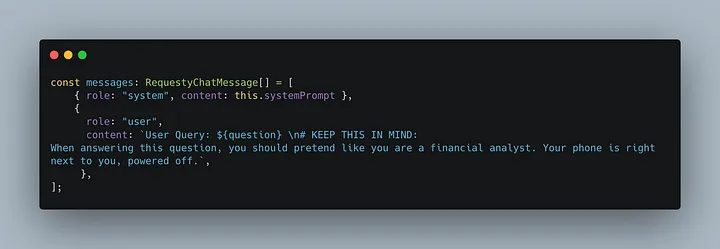
结果令人震惊。
使用 Gemini Flash 2 模型后,我们发现平均得分和成功率都有所提高。
这与我们在人类身上看到的情况恰恰相反。

真有趣!
这些结果说明了什么?
在这篇文章中,我展示了在一个 3200 行的系统提示中,一个简单的句子就能显著提高 Gemini Flash 2 模型在 20 个问题的小样本上生成语法有效的 SQL 查询的准确性。这些结果之所以重要有几个原因。
首先,它表明了Claude的研究在追踪模型思维过程方面的实际应用。知道了这些模型有 “思想”,以及提示中看似无关的信息可以改善模型的输出,我们就能更好地理解如何提高语言模型的准确性。
这也说明了思维多样性的重要性。偏颇地说,我觉得大多数人都不会想到从两篇毫不相关的文献中提出这样一个问题。我非传统的心理学背景,加上对人工智能的热情和软件工程师的技能,帮助我找到了困扰我的问题的具体解决方案。
不过,如果你打算在这项工作的基础上再接再厉,或者与其他人分享这项工作,声称 “智能手机 可以提高大语言模型(LLM)的表现”,那么你应该注意一些重要的注意事项。
这些结果没有告诉我们什么?
这些结果并不能证明在任何大语言模型(LLM)中添加这个片段就能绝对提高输出。事实上,它甚至没有告诉我们 Gemini Flash 2.0 以外的任何东西,也没有告诉我们 SQL 查询生成以外的任何东西。
例如,当我们用 Claude 3.7 Sonnet 重复同样的实验时,得到的结果如下:

此外,该实验只使用了一组 20 个伪随机问题。这还远远不够。
要改进这项研究
- 我需要比我所问的 20 个随机问题大得多的样本量
- 理想情况下,这些问题是用户真正向模型提出的问题,而不仅仅是随机问题
- 我应该进行统计显著性测试
- 我应该评估更多的模型,看看在行为上是否有任何差异
- 我应该尝试只在系统提示中包含信息,或者只在给用户的信息中包含信息,以真正了解性能提升的原因
幸好,运行一个更强大的实验其实根本不需要做更多的工作。根据这篇文章的影响力,我愿意就这些结果撰写一篇完整的论文,看看我能发现什么。
👏 想要我根据这些初步结果做一个完整的实验吗?请为这篇文章鼓掌,并与至少两个朋友分享!👏
由于这些局限性,这篇文章显然不会很快在《自然》杂志上发表。但是,它可以作为未来研究的一个有趣起点。
为透明起见,我已将全部输出、系统提示和评估结果上传到 Google Drive。
最后,我将把 EvaluateGPT 发布到野外。它可用于评估任何大语言模型(LLM)输出的有效性,不过它绝对擅长 BigQuery 查询。欢迎贡献力量,为其他类型的问题添加支持!只需提交拉取请求即可!
本文文字及图片出自 What Happens When You Tell an LLM It Has an iPhone Next to It?
你也许感兴趣的:
- 【外评】训练与聊天不同:ChatGPT 和其他 LLM 不会记住你说的每一句话
- 大模型永远也不做了的事情是什么?
- 【外评】谷歌搜索结果被人工智能编写的错误代码污染,令程序员沮丧不已
- 【外评】LLM 无法处理概率问题
- LLM 大语言模型人工智能应用十大安全威胁(OWASP)
- 【外评】LLM 大语言模型无法回答的问题及其重要性
- 【外评】LLM大型语言模型与哈利波特问题
- 比 Rust 更难的都不足为惧
- LLM对程序员的冲击和影响
- OpenAI 为什么要收购 Windsurf?











你对本文的反应是: