





TypeScript 迁移到 Go: 10 倍性能的背后到底是什么?
将近两周前,微软宣布将把 TypeScript 编译器从 JavaScript 移植到 Go,并承诺性能将提高 10 倍之多。这一消息像野火一样席卷了整个技术社区,从 TypeScript 的粉丝到语言战争的狂热爱好者都纷纷加入了讨论。
该公告提供了令人印象深刻的性能数据和雄心勃勃的目标,但仍有一些耐人寻味的细节未被探索。我们今天就来讨论这些细节。为什么是今天,而不是一周前?在《架构周刊》中,我们不需要急于求成的点击广告,不是吗?我故意想等喧嚣平静下来。
在标题数字之下,是一个值得解读的故事,涉及设计选择、性能权衡和开发工具的演变。
即使你对编译器不感兴趣,你也可以从系统设计中汲取适当的经验教训,比如:
- 超越标题性能要求
- 将技术与问题领域相匹配
- 了解运行时模型。
- 随着项目的发展重新考虑基础。
让我们从微软文章的标题开始,逐步解决这个问题。
“快 10 倍的 TypeScript”–嗯,不完全是
首先,让我们来澄清一下微软公告标题中可能会引起混淆的地方:
“快 10 倍的 TypeScript”。
它真的快吗?一旦微软发布用 Go 重写的新代码,你用 TypeScript 编写的应用程序会快 10 倍吗?
并非如此 GIF | Tenor
实际上变快的是 TypeScript 编译器,而不是 TypeScript 语言本身或 JavaScript 的运行时性能。你的 TypeScript 代码会编译得更快,但它在浏览器或 Node.js 中的执行速度不会突然快 10 倍。
这有点像在说
“我们让你的汽车快了 10 倍!”
,然后澄清他们只是让制造过程更快了–汽车本身的行驶速度还是一样的。这仍然很有价值,尤其是当你等车等了几个月的时候。
除了 “快 10 倍 “的标题
Anders Hejlsberg 的公告展示了令人印象深刻的数字:
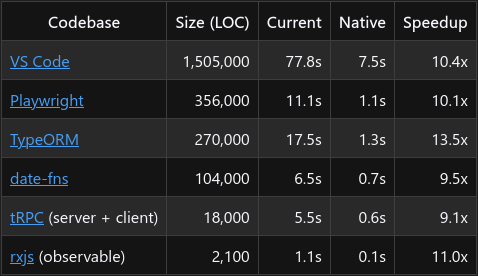
这些惊人的数据值得我们深入了解,因为这 10 倍的提速有多方面的因素。这不仅仅是 “Go 比 JavaScript 快 “这么简单。
老实说,每当你看到 “快 10 倍 “的说法时,你都应该抱着健康的怀疑态度来看待它。我的第一反应是:”好吧,他们之前做了什么次优的事情?因为 10 倍的改进不会凭空出现–它们通常表明,有些东西一开始就做得不够好。无论是实施还是某些设计选择。
人们普遍认为 “Node.js 很慢”,这与其说是事实,不如说是一种重复的刻板印象。在某些情况下,这种说法可能是对的,但并不具有普遍性。
如果有人说 “Node.js 很慢”,就好像他们说 C 和 C++ 很慢一样。为什么这么说呢?
Node.js 的架构
Node.js 基于谷歌的 V8 JavaScript 引擎构建,该引擎也是支持 Chrome 浏览器的高性能引擎。V8 引擎本身是用 C++ 编写的,Node.js 本质上是围绕它提供了一个运行时环境。这种架构是了解 Node.js 性能的关键:
- V8 引擎: 使用即时(JIT)编译技术将 JavaScript 编译为机器代码
- libuv: 处理异步 I/O 操作的 C 库
- 核心库: 许多库都是用 C/C++ 编写的,以提高性能。这也是为什么 Node.js、Go 和 Rust 中使用的数据库连接器性能几乎没有明显差异的原因。
- JavaScript API: 这些本地实现的薄型封装
当人们谈论 Node.js 时,往往没有意识到他们谈论的是一个由高度优化的 C/C++ 代码执行关键操作的系统。你的 JavaScript 通常只是协调对这些本地实现的调用。
有趣的事实:Node.js 多年来一直是速度最快的网络服务器技术之一。当 Node.js 首次出现时,它在基准测试中的表现超过了许多传统的线程网络服务器,尤其是在高并发、低运算量的工作负载方面。这并非偶然,而是设计使然。
内存绑定与 CPU 绑定
Node.js 是专门为网络服务器和网络应用程序设计的,这些应用程序主要是内存绑定和 I/O 绑定,而不是 CPU 绑定:
内存绑定操作包括移动数据、转换数据或存储/检索数据。想想看
- 解析 JSON 有效负载
- 转换数据结构
- 路由 HTTP 请求
- 格式化响应数据
I/O 绑定操作涉及等待外部系统:
- 数据库查询
- 网络请求
- 文件系统操作
- 外部 API 调用
对于典型的网络应用程序,大部分时间都在等待这些 I/O 操作完成。典型的请求流程可能是
- 接收 HTTP 请求(内存受限)
- 解析请求数据(内存受限)
- 查询数据库(I/O 受限,大部分时间在等待)
- 处理结果(内存受限)
- 格式化响应(内存受限)
- 发送 HTTP 响应(I/O 受限)
在这一工作流程中,实际的 CPU 密集型计算微乎其微。大多数网络应用程序 80-90% 的时间都在等待 I/O 操作完成。
Node.js 正是针对这种情况进行了优化,因为:
- 非阻塞 I/O: 在等待 I/O 操作的同时,Node.js 可以处理其他请求
- C++ 基础: 内存操作委托给高效的 C++ 实现
- Event Loop Efficiency: 善于协调多个并发操作,开销最小
很多人都忽略了这一点: Node.js 中的 I/O 密集型操作几乎以 C 级速度运行。当您在 Node.js 中发出网络请求或读取文件时,您基本上是在调用 C 语言函数和一个薄薄的 JavaScript 封装。
这种架构使 Node.js 成为网络服务器的革命性产品。如果使用得当,单个 Node.js 进程就能高效处理数千个并发连接,在典型的网络工作负载中,其性能往往优于按请求处理线程的模式。
Node.js从根本上源于这样一种理念,即多任务处理与人类任务一样,并不总是处理任务的最佳方式。同步多个任务和上下文切换会增加开销,而且并不总能带来更好的结果。这完全取决于能否将任务分割成可以同时完成的小块。
Node.js 面临的挑战: 与 CPU 相关的操作
Node.js 面临的真正性能挑战是 CPU 密集型任务,例如(再次欢迎!)编译 TypeScript。这些工作负载与 Node.js 优化所针对的网络服务器场景有着本质的不同。
CPU 绑定操作涉及大量计算,等待时间极短:
- 复杂算法和计算
- 解析和分析大型文件
- 图像/视频处理
- 编译代码
在这些场景中,瓶颈不是等待外部系统,而是原始计算能力和运行时执行算法的效率。
单线程限制
JavaScript 在设计时采用了单线程事件循环模型。这种模型最适合处理并发 I/O(大部分时间都在等待),但对于 CPU 密集型操作来说,就会出现问题:
// Pseudocode of how the Node.js event loop works
while (thereAreEvents()) {
const event = getNextEvent();
processEvent(event); // If this takes a long time,
// everything else waits
}当 CPU 密集型任务运行时,它会垄断这一个线程。在此期间,Node.js 无法处理其他事件、处理新请求,甚至无法响应现有请求。在计算完成之前,它实际上是被阻塞的。
这就是为什么在 Node.js 中运行复杂算法会导致整个网络服务器无响应的原因–事件循环忙于计算,无法处理传入请求。
事件循环
在 JavaScript 中编写高效的 CPU 密集型代码需要了解并尊重事件循环。代码的结构必须能够让渡控制权,使其他操作能够定期进行:
//////////////////////////////////////////////
// Naive approach - blocks the event loop
/////////////////////////////////////////////
function processLargeData(data) {
for (let i = 0; i < data.length; i++) {
// Heavy computation that might take seconds
processItem(data[i]);
}
return results
}
//////////////////////////////////
// Event-loop friendly approach
//////////////////////////////////
async function processLargeDataChunked(data) {
const results = []
const CHUNK_SIZE = 1000
for (let i = 0; i < data.length; i += CHUNK_SIZE) {
const chunk = data.slice(i, i + CHUNK_SIZE)
// Process one chunk
for (const item of chunk) {
results.push(processItem(item))
}
// Yield to the event loop before processing the next chunk
await new Promise(resolve => setTimeout(resolve, 0))
}
return results
}这种 “分块 ”方法虽然有效,但却带来了复杂性,并从根本上改变了代码的结构。这种编程模式与原生线程语言截然不同,在原生线程语言中,您可以编写直接的 CPU 密集型代码,而不必担心阻塞其他操作。
对于像 TypeScript 编译器这样复杂的应用程序来说,随着代码库的增长,这种与事件循环共舞的方式变得越来越难以管理。
编译器: 编译器:CPU 密集型怪兽
编译器实际上是 CPU 密集型工作负载的典型代表。它需要
- 将源代码解析为标记和抽象语法树
- 执行复杂的类型检查和推理
- 应用转换和优化
- 生成输出代码
这些操作涉及复杂的算法、大型内存结构和大量计算–正是这类工作对 JavaScript 的执行模型提出了挑战。
具体到 TypeScript,随着语言的复杂性和功能的不断增强,编译器必须处理越来越复杂的类型检查、推理和代码生成。这种发展自然会突破 JavaScript 运行时的效率极限。
线程模型的重要性: 事件循环与本地并发
JavaScript 和 Go 实现之间的性能差距不仅仅在于语言的原始速度,从根本上说,它还与线程模型以及它们如何与问题领域相匹配有关。
如前所述,Node.js 基于事件循环模型运行:
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
这种单线程方法意味着,对于像编译 TypeScript 这样的 CPU 密集型工作,你需要编写不会垄断线程的代码。在实践中,这需要将工作分解成较小的块,以便将控制权交还给事件循环。
这给编译器的设计带来了巨大挑战:
- 人为碎片化: 编译器各阶段的自然流程(解析 → 分析 → 转换 → 生成)需要分解成可以产生控制的小步骤。
- 复杂的状态管理: 由于处理过程在事件循环迭代中被分割开来,因此必须仔细管理编译器状态,并在生成之间保留编译器状态。
- 定位中断: 当事件循环在编译器操作之间处理不相关的任务时,CPU 缓存的本地性优势就会丧失,从而影响性能。
- 依赖性挑战: 编译器各组件之间存在复杂的相互依赖关系。为了适应事件循环,打破自然顺序流程往往需要复杂的协调逻辑。
Go 提供了由 Go 运行时管理的轻量级线程–goroutines:
┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐
│Goroutine│ │Goroutine│ │Goroutine│ │Goroutine│ ... more
└────┬────┘ └────┬────┘ └────┬────┘ └────┬────┘
│ │ │ │
└───────────┴───────────┴───────────┘
│
┌────────┴────────┐
│ Go Scheduler │
└────────┬────────┘
│
┌──────┴──────┐
│ OS Threads │
└─────────────┘
该模型允许编译器各阶段自然并行,协调开销最小:
- 自然并行: 可同时对不同文件进行解析和类型检查。
- 直接线程访问: CPU 密集型操作可直接在线程上运行,而不会产生迭代。
- 高效协调: Go 的通道和同步原语旨在协调并发工作。
- 内存效率: 与操作系统线程(每个线程数以 MB 计)相比,Goroutines 占用的内存极少(每个线程几 KB)。
在这种模式下,文件解析、类型检查和代码生成都可以并发进行,而无需显式屈服点。代码结构可以更自然地遵循编译器各阶段的逻辑流程。
相同的代码,不同的执行模型
Anders Hejlsberg 说,他们评估了多种语言,Go 是最容易移植到代码库中的语言。显然,TypeScript 团队已经创建了一个生成 Go 代码的工具,从而在许多地方实现了几乎逐行等价的移植。这可能会让你觉得这些代码 “做着同样的事情”,但这是个误解。
Theyre The Same Picture The Office GIF – Theyre The Same Picture The Office Pam – Discover & Share GIFs
代码可能看起来一样,但由于不同语言的执行模式不同,它们的表现也会大相径庭。
在 JavaScript 中:
- 所有代码都运行在带有事件循环的单线程上,
- ,长时间运行的操作需要分解或委托给工作线程,
- ,并发执行需要小心处理以避免阻塞事件循环。
在 Go 中
- 代码自然会在多个 goroutines(轻量级线程)上运行,
- ,长时间运行的操作可以在不阻塞其他工作的情况下执行,
- ,语言和运行时就是为并发执行而设计的。
当你在不改变代码结构的情况下将其从 JavaScript 移植到 Go 时,你隐含地改变了代码的执行方式。在 JavaScript 中会阻塞事件循环的操作,在 Go 中只需极少的工作量就能并发运行。
由此可以得出一个结论:当直接移植带来显著的性能提升时,可能表明原始实现没有针对 JavaScript 的执行模型进行完全优化。
编写真正高性能的 JavaScript 意味着要接受其异步特性和事件循环约束–这在复杂的代码库(如编译器)中变得越来越具有挑战性。
那么工作线程呢?
有些人可能会想
“Node.js现在不是已经有工作线程了吗?难道他们不能使用这些线程而不是迁移到 Go 吗?
这个问题很有道理。Node.js 在 v10 中引入了 Worker_threads 模块,作为一项实验性功能,在 v12(2019 年中期)成为稳定功能。工作线程在 Node.js 中提供了真正的并行性,允许 CPU 密集型任务在单独的线程上运行,而不会阻塞主事件循环。
工作线程在 Node.js 中的工作原理
与大多数 Node.js 应用程序的单线程事件循环不同,工作线程允许并行执行 JavaScript:
// main.js
const { Worker } = require('worker_threads')
function runWorker(workerData) {
return new Promise((resolve, reject) => {
const worker = new Worker('./worker.js', { workerData })
worker.on('message', resolve)
worker.on('error', reject)
worker.on('exit', code => {
if (code !== 0) {
reject(new Error(`Worker stopped with exit code ${code}`))
}
})
})
}
// Run multiple CPU-intensive tasks in parallel
Promise.all([
runWorker({ chunk: data.slice(0, middleIndex) }),
runWorker({ chunk: data.slice(middleIndex) })
]).then(results => {
// Combine results
}) // worker.js
const { parentPort, workerData } = require('worker_threads')
// Perform CPU-intensive work
const result = processData(workerData.chunk)
// Send the result back to the main thread
parentPort.postMessage(result)每个 Worker 都在自己的 V8 实例中运行,拥有自己的 JavaScript 堆,从而实现真正的并行。工作线程通过发送和接收消息与主线程(以及彼此)通信,其中包括转移某些数据类型的所有权,以避免复制。
为什么工作线程不是 TypeScript 的解决方案?
那么,为什么 TypeScript 团队会选择 Go,而不是用工作线程改造现有代码库呢?我们不得而知,但有几个貌似合理的原因:
- 遗留代码库的挑战: TypeScript 编译器已经开发了十多年。将为单线程执行而设计的大型成熟代码库改装为多线程架构往往比从头开始更为复杂。Worker 主要通过消息传递进行通信。要重构编译器,使其能以这种方式运行,就需要从根本上重新设计组件的交互方式。视频显示,即使是单线程 Go 也更快,因此代码可能仍需修改,以更好地照顾事件循环特性。
- 数据共享复杂性: Worker 共享内存的能力有限。编译器要处理的是复杂、相互关联的数据结构(抽象语法树、类型系统等),这些数据结构无法整齐地分割成孤立的块来进行并行处理。
- 性能开销: 工作线程在提供并行性的同时,也会带来开销。每个工作线程都有自己的 V8 实例和独立内存,线程之间传递的数据通常需要序列化和反序列化。它们不像线程或 goroutines 那样轻量级。
- 时间线不匹配: 在设计和实施 TypeScript 编译器时(2012 年左右),Node.js 中还不存在工作线程。早期所做的架构决策会假定采用单线程模型,从而使后来的并行化变得更加困难。
- 死胡同评估: 团队可能已经得出结论,即使有了工作线程,JavaScript 仍然会对他们的特定工作负载造成基本限制,最终再次成为瓶颈。
- 技能组合调整: 该决定可能在一定程度上反映了组织的专业知识以及与其他开发工具的战略一致性。
Go 方法与工作线程的对比
Go 的并发方法与 Node.js 的工作线程相比,在编译器工作负载方面具有以下几个优势:
- 轻量级 Gooutines: 与工作线程(需要单独的 V8 实例)相比,Goroutines 非常轻量级(起始内存约为 2KB),因此细粒度并行更加实用。
- 共享内存模型: Go 允许在具有同步原语的 goroutines 之间直接共享内存,这使得处理复杂、互连的数据结构变得更容易。
- 语言级并发性: Go 在语言层面通过 goroutines 和通道实现了并发性,使并行代码的编写和推理更加自然。
- 更低的通信开销: 与工作线程通信所需的序列化/反序列化相比,goroutines 之间的通信效率要高得多。
- 成熟的调度程序: Go 的运行时包含一个成熟、高效的调度程序,可在可用的 CPU 内核上管理数千个 goroutines。
此外,我认为迁移到 Go 并不仅仅是 “多线程与单线程 “的问题,而是采用了一种编程模型,在这种模型中,并发是一个一流的概念,并被深度集成到语言和运行时中。
进化问题
TypeScript 于 2012 年启动时,团队根据当时的环境做出了合理的技术选择:
- TypeScript 是微软对 JavaScript 的一个扩展项目,因此使用 JavaScript 是合理的
- 最初的范围和复杂度要小得多
- Go 和 Rust 等替代品仍处于早期阶段
- 性能需求比较适中
随着时间的推移,TypeScript 从 JavaScript 的一个相对简单的超集发展成为一种复杂的语言,具有高级类型特性、泛型、条件类型等。编译器也随之发展,但其基础仍然是为解决更简单的问题而设计的。
这是一个典型的例子,说明成功的软件往往会面临早期设计时没有预料到的扩展挑战。随着 TypeScript 编译器变得越来越复杂,并被应用到更大的代码库中,其 JavaScript 基础变得越来越受限制。
难道你自己不知道吗?
遗留代码是如何产生的?日复一日。
悬而未决的问题和未来考虑
虽然 Go 迁移带来的性能提升令人印象深刻,但微软的声明中还没有完全解决几个重要问题:
浏览器支持如何?
TypeScript 不仅可以在服务器和开发机器上运行,还可以通过各种 playground 实现和浏览器集成开发环境直接在浏览器中使用。由于 Go 无法在浏览器中原生运行,微软将如何解决这一用例?
有几种可能的方法:
- WebAssembly (WASM): 将 Go 实现编译成 WebAssembly 可以让它在浏览器中运行。虽然 WASM 的性能已大幅提高,但与本机 Go 相比,仍会有开销。
- 双重实现: 微软可能会为浏览器保留一个 JavaScript 版本,同时为其他一切保留 Go 版本。这将给功能均等和维护带来挑战。
- 浏览器专用替代方案: 他们可能会创建一个精简的浏览器特定实现,并针对常见的游戏场景优化减少功能。
- 云编译: 基于浏览器的工具可能会将代码发送到运行 Go 编译器的云端点,而不是在本地执行编译。
公告没有明确说明他们的方法,但这是一个将影响 TypeScript 生态系统的重要细节。
特性平价与性能权衡
值得注意的是,实现性能提升往往需要权衡。一种常见的方法是减少功能范围或复杂性。虽然微软声称他们保持了完全的功能均等,但我们应该仔细观察是否有任何细微的行为变化,或者是否对某些边缘情况进行了不同的处理。
其他语言迁移的历史案例表明,要实现 100% 的相同行为是非常困难的。一些需要考虑的问题
- 所有现有的 TypeScript 错误信息都会保持完全相同吗?
- 类型推理中的每种边缘情况都会表现相同吗?
- 编译选项和标志会有相同的效果吗?
- 性能优化会如何影响类型系统的边缘情况?
TypeScript 团队在向后兼容性方面有着良好的记录,但从头开始重写必然会带来细微行为变化的风险。
可扩展性和插件生态系统
TypeScript 拥有丰富的插件和工具生态系统,可以扩展编译器。向 Go 的迁移引发了有关该生态系统未来的问题:
- 插件 API 能否保持兼容?
- 基于 JavaScript/TypeScript 的插件是否需要用 Go 重写?
- 这将如何影响创建 TypeScript 工具的门槛?
这些考虑因素将影响更广泛的 TypeScript 生态系统,而不仅仅是编译性能。
为什么这与 TypeScript 无关
本案例研究对技术选择有更广泛的影响:
- 将技术与问题领域相匹配。CPU 绑定的任务(如编译器)受益于专为计算和本地线程设计的语言。网络服务器等受 IO 约束的任务通常可以很好地与事件循环模型配合使用。
- 随着项目的发展,重新考虑基础。在小型项目中行之有效的方法,在大规模项目中可能会成为制约因素。愿意重新审视基本架构决策。大胆尝试没有错,比如在必要时重写。但在此之前,请先阅读这篇文章。
- 不要只看标题性能。10 倍的性能提升 “往往有多个促成因素,而不仅仅是技术堆栈的变化。
- 了解您的运行时模型。无论您使用的是 Node.js、Go、Rust 还是其他环境,了解代码的执行方式对于性能优化都至关重要。
展望未来
作为 TypeScript 用户,构建 Emmett 和 Pongo 是个好消息。如果我能 “免费 ”让编译器运行得更快,那真是太好了。但另一方面,我不明白为什么我们要制造如此大的噪音,并用点击诱饵作为向开发社区宣传的一种方式。
只关注 10 倍而不提供足够的背景信息只会造成摩擦(我很仁慈地略过了 C# 开发人员 “为什么不使用 C#!”的呼声……)。
这就是为什么我想扩展这个用例,因为它提供了关于技术、语言选择、性能优化和成功项目演变的宝贵经验。
从 JavaScript 迁移到 Go 并不意味着 “Node.js 很慢”。最好将其视为一种认识,即不同的问题需要不同的工具。JavaScript 和 Node.js 在它们的设计初衷方面依然出色: 具有高并发需求的 IO 密集型网络应用。
当然,如果微软能更详细地解释这一点,而不是进行点击式宣传,效果会更好,但这就是我们生活的世界。
您怎么看?你在项目中遇到过类似技术演进的挑战吗?你是如何应对的?你是否曾经获得过 10 倍的惊人改进?你是如何应对的?
我很乐意在评论中听听您的想法!
本文文字及图片出自 TypeScript Migrates to Go: What's Really Behind That 10x Performance Claim?
你也许感兴趣的:
- 微软用 Go 重写 TypeScript 编译器:快 10 倍的 TypeScript
- 编程语言的选择
- 大多数人不明白为什么 Go 使用指针而不是引用
- Go语言有个“好爹”反而被程序员讨厌?
- 【外评】为什么人们对 Go 1.23 的迭代器设计感到愤怒?
- 【译文】Go语言性能从 1.0 版到 1.22 版
- Go 语言程序员的进化
- 【译文】面试时,有人问我喜欢Go语言什么?
- 4 秒处理 10 亿行数据! Go 语言的 9 大代码方案,一个比一个快
- 【译文】Go语言设计:我们做对了什么,做错了什么











你对本文的反应是: