





JavaScript中的数字
Mozilla开发者社区是我学习的重要途径,有一次逛到这个API看到Polyfill有几行代码:
var list = Object(this); var length = list.length >>> 0;
由于非CS的某野生专业出身,我对位运算符的了解比较模糊,大概能明白的只是list.length >>> 0对list.length做无符号右移,而返回值是>=0的整数,但背后的运算过程,就不能说得清楚了。复习了一下相关知识,做个笔记。
今天讨论什么?
本文,将尝试从现代计算机中对数字的存储和计算讨论起,这也注定,虽然题目叫”Numbers in JavaScript”,但是大量篇幅应该集中在编程语言中主要使用的数字处理的方式。万变不离其宗,懂了原理之后,对掌握各种语言围绕同样原理构建的Number也就轻松多了。当然,这其中就包括JavaScript。
先想几个问题吧:
- JavaScript的数字为什么有
0和-0? - JavaScript中的
NaN为什么互不相等? - JavaScript中的数字真的只有一种类型吗?
- JavaScript中常被诟病的
0.3 - 0.2 == 0.1原因是什么? - 数组的最大长度是多少?为什么是这个值?
- 上述问题,只有在JavaScript中有吗?
当下,计算机如此普及,我相信,即便非程序员也了解:计算机的世界只有0和1。而一个程序员应该了解:0/1组成的东西叫机器码,有原码, 反码, 补码等。而一个JS程序员应该了解:JS中的数字是不分类型的,也就是没有byte/int/float/double等的差异。而一个稍微研究ES规范的JS程序员应该了解:JS的number是IEEE 754标准下64-bits的双精度数值,而且ES中有ToInteger/ToInt32/ToUint32/ToUint16等Type Conversion。下面,我们就尝试着讨论一下这些。
从硬件的角度上讲,维护两个状态是相对容易的,比如一个二极管的导通或者截止,一个电脉冲的高或者低,从而在实现集成电路时候可以更加简单高效,所以计算机普遍使用0和1来存储和计算。那么,只有0和1,如何表示1234567890呢?这就涉及到机器码和真值。
机器码和真值
所谓机器码是指,整数在计算机中二进制形式。规则很简单,机器码的最高位(左第一位)表示数字的正负,0表示正数,1表示负数,其余位按照进制转换的规则表示具体数字。
所谓真值是指,机器码按照上述转换规则还原的带有正负的实际整数。
举例而言,用8-bits表示一个整数,则十进制的整数+6可表示为:00000110;十进制的数字-5可表示为10000101。这里说的+6和-5便是真值,而表示它们的二进制数便是机器码。再次注意,最高位只用于表示正负,比如10000101的真值是-5而非133,以及我们关于机器码和真值的讨论是基于整数范围的,浮点数在计算机中的存储方式与整数有很大差值,将另作讨论。
有了机器码,我们便可以在计算机中使用机器码存储和计算真值,那么机器码在计算机中是如何计算的呢?
原码、反码、补码
机器码分为多种,主要包括原码、反码、补码、移码等,今天我们主要总结一下前三个,而移码非常简单,且多用于比较,不做详细说明。另外需要补充一点,我们在此区分机器码的这么多种形式,主要是针对的有符号数,而无符号数,不需要使用最高位来表示正负,也就不需要这么多种编码方式。
原码:
最高位表示正负,其它位表示真值的绝对值。其中,最高位为0表示正数或者0,为1表示负数。
比如,同样以8bits长度的数串表示+7的原码为0000 0111,-7的原码为10000111。以后,我们会这样表示:
[+7] = [00000111]原 [-7] = [10000111]原
很明显,8-bits的原码能记录的范围为:[-127,+127].
原码的好处在于,易于理解,相对直观,方便人脑识别和计算。
对于原码,人脑使用,可以直接计算出其真值然后可以进行后续操作。但对于计算机,首先,因为最高位用于表示正负,所以不能直接参与运算,需要识别然后做特殊处理;其次,具体计算使用绝对值进行操作,所以两个操作数正负的异同会影响操作符,比如两个异号相加实际要做减法操作,甚至异号相减还需要判断绝对值大小然后决定结果正负。如此,我们计算机的运算器设计将会变得异常复杂。下面,我们将了解如何使用反码和补码将符号位参与运算,从而使加减法统一简单高效地处理,这也是反码和补码出现的原因。
反码:
正数的反码等于其原码,而负数的反码则是对其原码进行符号位不变,其它位逐一取反的结果。
比如,同样以8-bits长度的数串表示+7,那么有如下:
[+7] = [00000111]原 = [00000111]反 [-7] = [10000111]原 = [11111000]反
同样,8-bits的反码能记录的范围为:[-127,+127]。
在按位取反之后,我们可以有下面的操作:
2 - 3 = 2 + (-3)
= [00000010]原 + [10000011]原
= [00000010]反 + [11111100]反
= [11111110]反 = [10000001]原
= -1
上面,我们将减法通过反码转化为了加法,如此,我们的运算将会简单很多,但是反码的方式同样存在一些问题:
3 - 3 = 3 + (-3)
= [00000011]原 + [10000011]原
= [00000011]反 + [11111100]反
= [11111111]反
= [10000000]原
= -0
出现了-0,这个值是没有意义的。另外,按照反码加法法则,如果最高位有进位,需要在最低位上+1,那么会出现:
3 - 2 = 3 + (-2)
= [00000011]原 + [10000010]原
= [00000011]反 + [11111101]反 (这里最高位有进位,需要在最低位+1)
= [00000001]反
= [00000001]原 = 1
这种情况,又增加了反码运算的复杂性,影响效率,为解决上面的问题,出现了补码。
补码:
正数的反码等于其原码,而负数的补码则是对其反码进行末位加1的结果。
比如,再同样以8-bits长度的数串表示+7,那么有如下:
[+7] = [00000111]原 = [00000111]反 = [00000111]补 [-7] = [10000111]原 = [11111000]反 = [11111001]补
使用补码,继续做之前的操作:
2 - 3 = 2 + (-3)
= [00000010]原 + [10000011]原
= [00000010]反 + [11111100]反
= [00000010]补 + [11111101]补
= [11111111]补
= [11111110]反
= [10000001]原
= -1
那么,如果是3-3呢?
3 - 3 = 3 + (-3)
= [00000011]原 + [10000011]原
= [00000011]反 + [11111100]反
= [00000011]补 + [11111101]补
= [00000000]补
= [00000000]原
= 0
是否还需要做额外的加法操作?
3 - 2 = 3 + (-2)
= [00000011]原 + [10000010]原
= [00000011]反 + [11111101]反
= [00000011]补 + [11111110]补
= [00000001]补
= [00000001]原
= 1
这样,我们便可以完美的将减法统一到加法之上,而且不需要繁琐的正负判断,进位控制,甚至可以节约一个位置。那么,这个位置,也就是10000000如何处理呢?按照规定,10000000用来表示-128,正数的补码/反码/原码相同,而负数的补码只是占用了-0的[10000000]原和[11111111]反转换后得到的[10000000]补表示-128,但是这个只是帮助理解,不能反向回推得到-128的原码和补码。
所以,8bits的补码能记录的范围为:[-128,+127]。
至此,我们已经了解了,计算机中主要使用的存储和计算整数的方式,鉴于现代计算机主要使用补码方式,自然能很容易理解各种数字类型的表示范围,比如32bits的int范围为:[-231,231-1]。这对于我们后面理解一些JavaScript中的极端情况至关重要。
稍加补充:
我们可能会想,原码很容易接受的,可是反码和补码的出现是基于什么样的逻辑或者数学原理呢?这里,我们可以蜻蜓点水地讨论一下,因为这个tread已经超出今天话题有点多了。
常用来说明这个原理的例子是时钟,时钟的一周有12个数字,那么,如果我们希望从3调整到8该如何操作?可以往前+5,也可以往后-7。这里的两个数字,+5和-7存在着的关系:它们同时对数字12求余数得到同样的结果。严格的概念是我们小时候学习的同余,准确的描述上面的关系是+5和-7对模12同余,+5和-7是互补关系,互为补码。我们可以看出,在模的数字范围之内,我们减去一个数字,恰好等于加上这个数字的补码然后取余。大致就这么描述一下,详细的过程是需要严谨的科学证明,网上有大量的文献,在此我们适时收住点到为止,有兴趣的同学自行google吧。
IEEE 754标准
作为一个JavaScript程序员,我们只有一个Number,所以我们从一开始就习惯了:
var num1 = 123; var num2 = 1.23;
但是,你知道JS的number是IEEE 754标准的64-bits的双精度数值吗?这是一个什么样的标准?使用这个标准的64-bits双精度意味着什么?所以,要掌握JavaScript中的数字,我们首先得了解IEEE 754标准。下面,我将尝试说明一下这个标准,为我们最后学习JavaScript中的数字做铺垫。
标准的基本原理:
我们知道,对于计算机而言,数字没有小数和整数的差别,也就是计算机中没有小数点的存在。通过前文的讨论,我们已经找到了很完美的整数存储计算的方案,但是当涉及到小数,我们很容易发现,现有的方案无法解决我们的需求。然后,计算机科学家们便尝试了多种方案,主要便是定点数和浮点数两种。
所谓定点数,是指小数点位置固定在数串中间的某个特定位置,点两侧分别为数字的整数和小数部分。比如用8-bits字长的数串,小数点固定在正中间位置,那么11001001和00110101分别表示1100.1001和11.0101两个数字。这种方案简单直观易理解,但是存在严重的空间浪费,以及容易溢出的问题。
所谓浮点数,是指小数点的位置是不固定的,通过科学计数法(这个应该不需要解释吧)的方式控制小数点的位置,表示不同的数字。这个表示方案便是IEEE 754标准使用的方案。IEEE 754标准是目前使用最广泛的浮点数运算标准。下面我们将主要讨论一下此方案。
现在,让我们想一下小时候学习的科学计数法,比如-123.456这个数字,转换成科学计数法应该是:-1.23456 × 10^2。这里面已经包含了IEEE 754标准的主要元素。我们梳理一下:第一个,自然是正负号的问题,需要一个标志;然后,需要一个具体的数字,表示有效数字或者精度,如上例的1.23456;再然后,需要一个控制小数点位置的数字,如上例的10^2,回忆一下,我们学习科学计数法的时候,要求前面的数字的绝对值大于1而小于10,也就是小于10^2中的底数(Base),进制固定之后,底数应该是固定的,所以这里起决定作用的是指数,也就是上例中的2。那么,有了这三个元素,我们便可以很轻松的表示出一个数字,并且灵活的调节小数点位置从而控制数字正负、精度和大小。
上面的要素,转换成标准语言描述,我们称表示正负的标志叫符号(Sign),表示精度的数字为尾数(Mantissa)或者有效数字(Significand),而控制小数点位置的指数就叫指数(Exponent),指数和基数(Base)共同作用参与计算。下图取自wikipedia,我们直观地感受下这三个要素在一个数串中的相对关系(fraction区域即等同于前面说的有效数字区域):

了解最基本的原理后,我们来大致看一下IEEE 754标准做了什么。
首先做的事情就是规定这三个要素在一个数串中占有的位数,试想一下,如果各个实现的位数不确定,那么我们是不是很难正确的还原出原始数字?IEEE 754标准规定了四种表示浮点数值的方式:单精确度(32位)、双精确度(64位)、延伸单精确度(43比特以上,很少使用)与延伸双精确度(79比特以上,通常以80比特实做)。只有32位模式有强制要求,其他都是选择性的。而现在主流的语言,多提供了单精度和双精度的实现,我们在此主要比较一下这两者,如图是它们各个部分对应上图,所使用的位数如下:
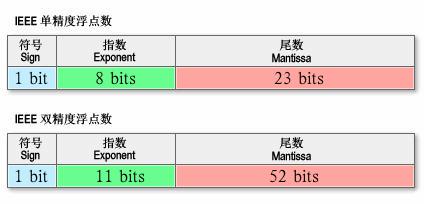
补充一点的是,无论是科学计数法还是标准的规定,都要求有效数字(不考虑符号位)必须>=1 && <Base。所以,有效数字其实是一个定点数,小数点的位置固定在有效数字域的最高位和次高位之间。那么,按照上述规定,在二进制中,最高位只能是1,所以标准要求省略其最高位,于是精度提高一位。比如,32-bits的单精度有效数字区域只有23位,但是精度却是24位;64-bits的双精度,拥有52位的有效数字域却是54位精度的。
然后,还有一个问题,如果按照先有的约定,是不是无法表示小于1的实数?因为,指数一定>=0,有效数字一定>1。于是,IEEE 754标准提出了一个很重要的指数偏移值。它是说明指数域(Exponent占用的区域)的编码值为指数的实际值加上某个固定的值,换言之便是,如果我们根据指数域计算出的指数是N,那么参与计算实际浮点数的指数应该是N-指数偏移值。根据IEEE 754标准的规定,该固定值为2^(e-1) - 1,其中的e为存储指数的比特的长度。比如,从上图中我们看到,32-bits的单精度是以8-bits表示一个指数域,那么偏移值应该是2^(8-1) - 1 = 128−1 = 127。所以,容易得出,单精度浮点数的指数部分实际取值是[-127,128]。比如,某个32-bits单精度的指数为十进制的1,那么指数域的编码应该是10000001,某个32-bits单精度的指数域编码是00000001,那么该指数的实际值应该是十进制的-126。这样,我们就能通过偏移值将正指数转换为负指数,从而使浮点数能逼近0。浮点数的指数计算跟前面讨论的机器码恰好相反,正数的最高位都是1,而负数的最高位都是0。
以上的描述,便是IEEE 754标准最需要我们了解的原理部分,但是,作为一个广泛使用的工业标准,规定这些还是远远不够的。
稍加补充:
wikipedia对IEEE 754标准有如下描述:
这个标准定义了表示浮点数的格式(包括负零-0)与反常值(denormal number)),一些特殊数值(无穷(Inf)与非数值(NaN)),以及这些数值的“浮点数运算符”;它也指明了四种数值舍入规则和五种例外状况(包括例外发生的时机与处理方式)。
下面,补充几个,我认为与本文后续讨论相关的或者可以帮助大家理解极端现象的定义:
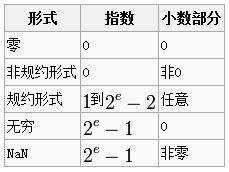
规约形式的浮点数:如果浮点数中指数部分的编码值在0 < exponent < 2^(e-1)之间,且尾数部分最高有效位(即整数字)是1,那么这个浮点数将被称为规约形式的浮点数。也就是,严格按照我们上文描述编码的数字。
非规约形式的浮点数:如果浮点数的指数部分的编码值是0,尾数为非零,那么这个浮点数将被称为非规约形式的浮点数。IEEE 754标准规定:非规约形式的浮点数的指数偏移值比规约形式的浮点数的指数偏移值大1.例如,最小的规约形式的单精度浮点数的指数部分编码值为1,指数的实际值为-126;而非规约的单精度浮点数的指数域编码值为0,对应的指数实际值也是-126而不是-127。实际上非规约形式的浮点数仍然是有效可以使用的,只是它们的绝对值已经小于所有的规约浮点数的绝对值;即所有的非规约浮点数比规约浮点数更接近0。规约浮点数的尾数大于等于1且小于2,而非规约浮点数的尾数小于1且大于0.
上面的两个概念,几乎是直接从wikipedia上扒下来的,非规约形式的浮点数出现的意义是避免突然式下溢出(abrupt underflow),而采用渐进式下溢出。这已经是上世纪70年代的事情了,差不多是我的年龄的两倍了。这个是一些非常极端的情况,在此我尝试最简单地描述一下非规约形式的浮点数出现的意义,知道有这么回事便可:下面,以单精度为例,如果没有非规约形式的浮点数,那么绝对值最小的两个相邻的浮点数之间的差值将是绝对值最小的浮点数的2^23分之一,大家想一下,绝对值次小的浮点数减去绝对值最小的浮点数的值是多少?
1.00...01 × 2^(-126) - 1.00...00 × 2^(-126) = 0.00..01 × 2^(-126)
= 1 × 2^(-126-23)
= 2^(-149)
很明显,绝对值最小的规约数无法表达其和次小的规约数的差值,所以很容易导致有若干数字之间的差值下溢,可能会触发意料之外的后果。而如果采用非规约形式的浮点数,指数全0,偏移值比规约数偏移值大1(-126比-127大1),尾数小于1,那么非规约数能表达的最小值便是:
0.00..01 × 2^(-126) = 1 × 2^(-126-23)
= 2^(-149)
所以,非规约形式的浮点数解决了前述的突然式下溢出(abrupt underflow)而被标准采纳。
IEEE 754标准还规定了三个特殊值:
- 指数全0且尾数小数部分全0,则这个数字为±0。(符号位决定正负)
- 指数为2e – 1且尾数的小数部分全0,这个数字是±∞。(符号位决定正负)
- 指数为2e – 1且尾数的小数部分非0,这个数字是NaN。
结合前面的规约数,非规约数以及三个特殊值,可以得到如下总结:
现在,让我们回忆一下,各种语言中普遍描述的双精度浮点数的范围:[-1.7 × 10-308,1.7 × 10308]。打个岔,想象一个有300多位的十进制数字的适用情形,私以为远超过普通人想象力的边界。这个范围为什么是这个范围呢?我觉得,通过上面的讨论,大家应该能清晰,1.7/308这些数字出现的必然原因。
首先,我们应该很容易根据偏移量得出双精度浮点数的计算公式:
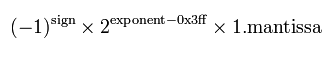
然后,以正数为例,按照上述特殊值中±∞和NaN的约定,指数的最大值应该满足指数取规约数的指数范围的最大值,然后小数部分取小数部分的最大值,可以得出这个二进制的数字应该是:
0 11111111110 11..11(52个)
转换为16进制表示:
0x7fef ffff ffff ffff
那么,根据前述规约数的原理,反编码便得到十进制的:1.7976931348623157 x 10^308。类似的道理,Sign位取反,便是范围的下限。
到此为止吧,我对IEEE 754标准也是最近几天稍加学习,再说多了就误导大家了。通过这几天的学习,我感觉,我们在理解的IEEE 754标准及浮点数的时候,要特别注意将精度和范围两个概念分别开来。范围只是一个模糊的界限,精度才是能准确表达的数字。
回到JavaScript
在上面的讨论中,我们很少提及JavaScript,似乎有点背离今天的主题了,但是,在了解了前述的原理之后,我们对JavaScript中数字的把握将”水到渠成”。这终将是一次,铺垫多于正文,开胃菜多于正餐的讨论。嗯,快喊小伙伴,正餐开始了!
ES的”The Number Type”:
现在,我们打开ES规范的“The Number Type”是不是基本通读下来了?
比如:
The Number type has exactly 18437736874454810627 (that is, 264 − 253 + 3) values…
为什么是这个数字?因为,我们说JavaScript中的数字是64-bits的双精度,所以首先有2^64中可能的组合,然后,按照前述的IEEE 754标准的标准中的特殊值中的部分,NaN和±∞占用了2^53个数值,但是表示了三个直观的量,所以,加减一下,自然就是18437736874454810627 (that is, 2^64 − 2^53 + 3) values。
…the 9007199254740990 (that is, 253−2) distinct “Not-a-Number” values…
为什么这么多NaN?同样,按照前述的IEEE 754标准的标准中的特殊值中的部分,NaN使用了Significand非零、指数是特定2^e-1且Sign无要求的所有可能,即2^53减去±∞两种情况。
…e is an integer ranging from −1074 to 971…
为什么指数的范围是这个呢?而不是-1022到+1022呢?因为,ES演化了一下公式,对比一下我们之前演示64-bits的公式,关于参与计算的mantissa,我们按照IEEE 754标准在演示的时候中使用的是1.m,而ES规范中使用的是m,当然会有尾数域bit长度的差异了。
到这里,关于数字,大概就可以结束了。开篇的几个问题,相信读到这里的同学,都能有答案了。但是,还有一个问题,JavaScript中的数字真的只有一种类型吗?,而且貌似到现在与我们的初衷,理解>>>有点偏离了。不过,世界上很多事情往往都是这样,解释原理需要到口干舌燥,而用原理去解释现象却只需要三言两语。
JavaScript不是只有64-bits的双精度
是的,小标题已经回答了我们的问题,JavaScript不是只有64-bits的双精度。我们通篇都在说JavaScript中数字的各种,一直按照64-bits的双精度来描述,但是,如之前所说,ES中有ToInteger/ToInt32/ToUint32/ToUint16等Type Conversion。这些Type Conversion不是我们直接调用的API,而是语言引擎在进行某些特定操作的时候,替我们做的。这种“隐形的操作”,只有在一些极端的情况下,会表现出来。现在,我们可以到“ToInt32”/“ToUint32”/“ToInt16”三个地方看一下,稍作比较便能发现,他们的差异很小,只是在特定的步骤中存在差异。比如,ToUint32和ToUint16
的差异仅仅操作的最后一步存在差异,按顺序列出比较一下:
Let int32bit be posInt modulo 232; that is, a finite integer value k of Number type with positive sign and less than 232 in magnitude such that the mathematical difference of posInt and k is mathematically an integer multiple of 232.
Return int32bit.
vs
Let int16bit be posInt modulo 216; that is, a finite integer value k of Number type with positive sign and less than 216 in magnitude such that the mathematical difference of posInt and k is mathematically an integer multiple of 216.
Return int16bit.
比较一下,不难发现,仅仅是2^32和2^16的差异,而关键点恰是modulo操作的时候,按照我们之前讨论的原理,很容易理解这个操作决定了可能出现的最大数。这样的比较,有一好处,能提高我们阅读标准的速度,而且加深理解,对掌握标准很有帮助。
总结一下这三个操作的范围:
ToInt32的范围便是其它强类型语言中的[-231, -231 – 1]。
ToUint32的范围便是其它强类型语言中的[0, -232 – 1]。
ToUint16的范围便是其它强类型语言中的[0, -216 – 1]。
通过搜索,很容易能找到,JavaScript中那些操作中使用了上述相关的操作。其中,ToUint16仅仅在String.fromCharCode中有使用,我们不做讨论了。ToInt32有在多个位运算符中使用,比如~ / << / >>,以及在parseInt也有使用。而ToUint32的使用则出现在了大量的地方,主要分布在,数组相关的操作,位运算的操作两个区域。
我们就借ToUint32的这些使用,回到开篇讨论的那个地方吧:
首先,来到这里>>>,看到操作如下:
1.Let lref be the result of evaluating ShiftExpression.
2.Let lval be GetValue(lref).
3.Let rref be the result of evaluating AdditiveExpression.
4.Let rval be GetValue(rref).
5.Let lnum be ToUint32(lval).
6.Let rnum be ToUint32(rval).
7.Let shiftCount be the result of masking out all but the least significant 5 bits of rnum, that is, compute rnum & 0x1F.
Return the result of performing a zero-filling right shift of lnum by shiftCount bits. Vacated bits are filled with zero. The result is an unsigned 32-bit integer.
再看new Array (len),有一句:
If the argument len is a Number and ToUint32(len) is equal to len, then the length property of the newly constructed object is set to ToUint32(len). If the argument len is a Number and ToUint32(len) is not equal to len, a RangeError exception is thrown.
对比不难发现,>>>的返回值和array.length的取值范围,无差异,经过>>>操作后的数字,一定是一个合法的array.length。解释原理总是那么复杂,可是用原理解释现象总是那么简单。
本文文字及图片出自 jser.it
你也许感兴趣的:
- JavaScript 框架选择困难症仍在增加
- 【程序员搞笑图片】盒子里有什么?javascript
- Node.js之父ry“摇人”——要求Oracle放弃JavaScript商标
- JavaScript 之父联手近万名开发者集体讨伐 Oracle:给 JavaScript 一条活路吧!
- 立即让JavaScript获得自由!JS之父等超8000人喊话Oracle:你们也不用,放手吧!
- ECMAScript 2024新特性
- 【外评】JavaScript 变得很好
- 一长串(高级)JavaScript 问题及其解释
- 不存在的浏览器安全漏洞:PDF 中的 JavaScript
- Python 里的所有双下划线(dunder)方法、函数和属性











长文, 翻译辛苦了