





具有魔法的 H.264
H.264 和 H.265 的许可证不相同。个人使用 H.264 是免费的,但商业使用 H.264 通常需要向一个实体支付许可费用,而 H.265 则需要向多个实体支付费用,因此会更加昂贵。在兼容性方面,H.265 超过了 H.264,但在普及率方面却落后于 H.264。H.264 得到了更多设备和浏览器的支持,而支持 H.265 的设备和浏览器则较少。这主要是因为 H.265 的专利问题阻碍了它的普及。
H.264 是一种视频压缩编解码标准。它无处不在–互联网视频、蓝光、手机、监控摄像头、无人机,无所不包。现在一切都使用 H.264。
H.264 是一项了不起的技术。它是 30 多年工作的成果,目标只有一个:减少全动态视频传输所需的带宽。
从技术上讲,它非常有趣。这篇文章将深入浅出地介绍其中的一些细节–我希望不会让你对错综复杂的细节感到厌烦。另外请注意,这里解释的许多概念适用于一般的视频压缩,而不仅仅是 H.264。
为什么要压缩?
一个简单的未压缩视频文件将包含一个 2D 缓冲区数组,其中包含每帧的像素数据。因此它是一个三维(2 个空间维度和 1 个时间维度)字节数组。每个像素需要 3 个字节来存储–三原色(红、绿、蓝)各一个字节。
1080p @ 60 Hz = 1920x1080x60x3 => ~370 MB/秒的原始数据。
这几乎是无法处理的。一张 50GB 的蓝光光盘只能存储 ~2 分钟。你无法快速移动它。即使是固态硬盘也很难将这些数据从内存直接转存到磁盘[^1]。
所以是的。我们需要压缩。
为什么要使用 H.264 压缩?
是的,我会回答这个问题。但首先让我给你看点东西。这是苹果公司的主页:
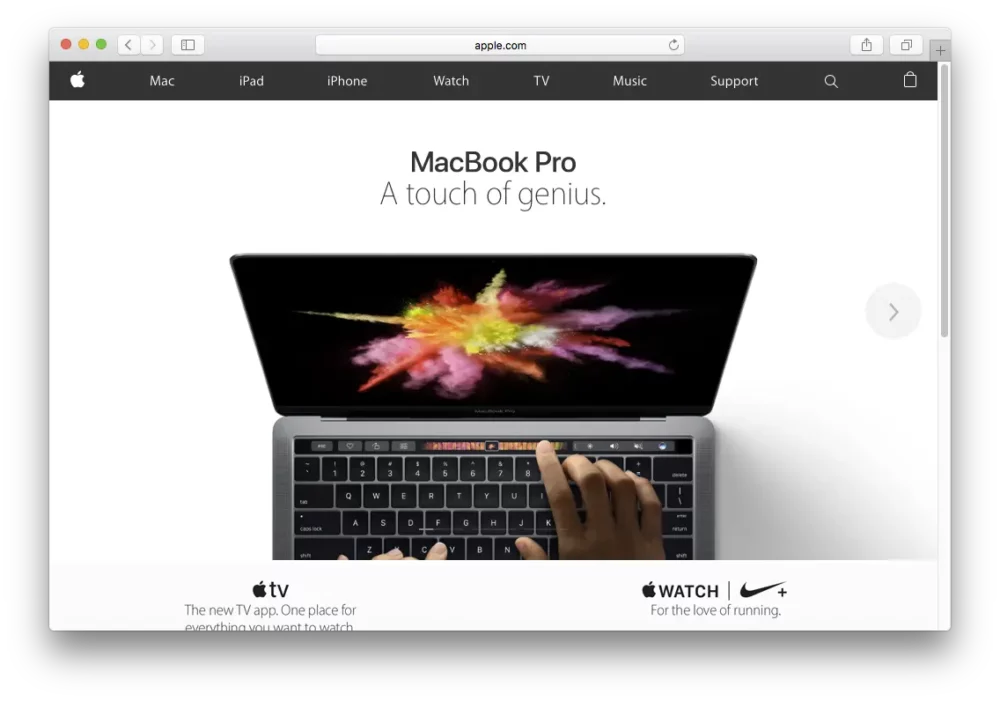
我截取了这个主页的屏幕,并生成了两个文件:
什么?这些文件大小看起来被调换了
不,它们是对的。300 帧长的 H.264 视频是 175KB。而 PNG 格式的单帧视频则为 1015KB。
看起来我们存储的数据量是视频的 300 倍。但文件大小只有五分之一。因此,H.264 的效率似乎是 PNG 的 1500 倍。
这怎么可能?好吧,有什么诀窍?
窍门非常多!H.264 使用了所有你能想到的技巧(还有很多你想不到的)。让我们来看看重要的窍门。
降低质量
想象一下,你正在制造一辆街头赛车。你需要跑得更快。你要做的第一件事是什么?减重。你的车重 3000 磅。扔掉不需要的东西那些后座?扔掉低音炮?没了没音乐了空调?对,扔了变速箱?不行等等,我们需要那个
除了重要的东西 你把其他东西都拿走
这种丢弃不需要的比特以节省空间的概念被称为有损压缩。H.264 就是一种有损压缩编解码器–它丢弃不重要的比特,只保留重要的比特。
PNG 是一种无损编解码器。这意味着不会丢失任何内容。可以从 PNG 编码图像中逐位恢复原始源图像。
重要比特?算法如何知道帧中哪些比特是重要的?
几乎没有什么明显的方法可以裁剪出图像。也许右上角的象限一直都没有用。因此,也许我们可以将这些像素清零,丢弃这个象限。这样我们只需使用所需的 3/4 空间。~现在约为 2200 磅。或者我们可以在画面边缘裁剪出一个厚边框,反正重要的东西都在中间。是的,你可以这样做。但 H.264 做不到这一点。
H.264 实际做了什么?
H.264 和其他有损图像算法一样,会丢弃细节信息。下面是原始图像与丢弃后图像的特写对比。
 看到压缩后的照片没有显示 MacBook Pro 扬声器格栅上的孔了吗?如果不放大,你甚至会注意到其中的差别。右边的图片只有原图的 7%,我们甚至没有对图片进行传统意义上的压缩。想象一下,你的汽车只有 200 磅重!
看到压缩后的照片没有显示 MacBook Pro 扬声器格栅上的孔了吗?如果不放大,你甚至会注意到其中的差别。右边的图片只有原图的 7%,我们甚至没有对图片进行传统意义上的压缩。想象一下,你的汽车只有 200 磅重!
7% 哇你是如何丢弃这样的细节信息的?
为此,我们需要上一堂快速数学课。
信息熵
现在,我们开始进入正题!哈,双关语!如果你上过信息论课,你可能会记得信息熵。信息熵是表示某些信息所需的比特数。请注意,它不仅仅是某个数据集的大小。它是表示数据集中包含的所有信息所必须使用的最小比特数。
例如,如果您的数据集是一次掷硬币的结果,那么您需要 1 位熵。如果您记录了两次抛硬币的结果,则需要 2 个比特。明白了吗?
假设你有一枚奇怪的硬币–你扔了 10 次,每次都是人头。你会如何向别人描述这一信息呢?你不会说 HHHHHHH。你只会说 “扔了 10 次,全是人头”–咣当!你刚刚压缩了一些数据!简单。我帮你省去了几个小时的头脑风暴讲座。这显然过于简单化了,但你已经把一些数据转换成了相同信息的另一种更简短的表达方式。你减少了数据冗余。这个数据集中的信息熵并没有改变–你只是在表述之间进行了转换。这种编码器被称为熵编码器–它是一种通用的无损编码器,适用于任何类型的数据。
频率域
既然你已经了解了信息熵,那我们就来谈谈数据的转换。你可以用一些基本单位来表示数据。如果使用二进制,则有 0 和 1;如果使用十六进制,则有 16 个字符。你可以很容易地在这两种系统之间进行转换。它们在本质上是等价的。到目前为止还不错吧?好吧!
现在来点想象力!想象一下,你可以将任何随空间(或时间)变化的数据集(比如图像的亮度值)转换到不同的坐标空间。因此,我们可以用频率坐标来代替 x-y 坐标。这就是所谓的频域表示法。还有一个让人匪夷所思的数学定理[^2]指出,只要 freqX 和 freqY 足够高,就可以对任何数据进行无损变换。
好吧,但 freqX 和 freqY 是什么频率?
freqX 和 freqY 是另一套基本单位。就像我们从二进制转换到十六进制时,我们有了不同的基本单位,我们从熟悉的 X-Y 转换到 freqX 和 freqY。十六进制的 “A “和二进制的 “1010 “看起来是不同的。两者的含义相同,但外观不同。下面是我们的图像在频域中的样子:

MacBook pro 上的细格栅在图像的高频成分中具有很高的信息含量。细微变化的内容 = 高频成分。色彩和亮度的任何渐变–如渐变–都是图像的低频成分。任何介于两者之间的成分都属于低频成分。因此,精细 = 高频。柔和的渐变 = 低频明白了吗?
在频域表示法中,低频成分靠近图像中心。高频成分则靠近图像边缘。
好吧有点道理但为什么要做这些呢?
因为现在,你可以获取频域图像,然后屏蔽掉边缘–丢弃包含高频成分的信息。现在,如果你将其转换回常规的 x-y 坐标,你会发现得到的图像看起来与原始图像相似,但失去了一些精细的细节。但现在,图像只占据了一小部分空间。通过控制遮罩的大小,你现在可以精确地调整输出图像的细节。
下面是首页中笔记本电脑的特写。只不过现在应用的是圆形边框蒙版。

这些数字表示该图像的信息熵为原始图像的一部分。即使是 2%,你也不会注意到其中的差别,除非你的变焦级别达到了这个水平。2%!- 你的车现在重 60 磅!
这就是减轻重量的方法。有损压缩中的这一过程被称为量化[^3]。
好吧,我猜你很厉害,你还有什么发现?
色度子采样
人眼的大脑系统并不擅长分辨色彩的细节。它可以很容易地检测到亮度的细微变化,但无法检测到色彩。因此,必须有某种方法来舍弃色彩信息,以减轻重量。
在电视信号中,R+G+B 色彩数据被转换为 Y+Cb+Cr。Y 是亮度(本质上是黑白亮度),Cb 和 Cr 是色度(颜色)成分。就信息熵而言,RGB 和 YCbCr 是等价的。
为什么不必要地复杂化?RGB 对你来说不够好?
在有彩色电视之前,我们只有 Y 信号。工程师们没有使用两个独立的数据流,而是明智地决定将色彩信息编码成 Cb 和 Cr,然后与 Y 信息一起传输。这样,黑白电视只能看到 Y 分量。彩电则会查看色度分量,并在内部转换为 RGB。
但请看其中的诀窍:Y 分量以全分辨率编码。而 C 分量只有四分之一的分辨率。由于眼睛/大脑对色彩变化的检测能力很差,因此可以避免这种情况的发生。这样一来,总带宽就减少了一半,而视觉差异却很小。一半!你的汽车现在重 30 磅!
这种舍弃部分色彩信息的过程称为色度子采样[^4]。虽然它不是 H.264 特有的,而且已经存在了几十年,但几乎被普遍使用。
这些都是有损压缩的主要减重方法。由于我们舍弃了大部分细节信息和一半的色彩信息,我们的帧现在变得非常小。
等等,就这样?就这样?我们能再做点什么吗?
可以。减重只是第一步。到目前为止,我们只查看了单帧图像中的空间域。现在是探索时间压缩的时候了–在这里,我们观察的是一组跨时间的帧。
运动补偿
H.264 是一种运动补偿压缩标准。
运动补偿?现在怎么办?
想象一下,你正在观看一场网球比赛。摄像机固定在某个角度。唯一移动的是来回移动的球。你会如何编码这些信息?就像往常一样,对吧?你有一个三维像素阵列,两个空间维度和一个时间维度。对不对?
不对你为什么要这么做?反正大部分图像都是一样的球场、球网、人群,都是静态的。唯一真正的动作是球在移动。如果只用一张静态的背景图片,然后只用一张移动的球的图片呢?这样不是可以节省很多空间吗?明白我的意思了吗?明白了吗?明白我的意思了吗?运动估算?
撇开无聊的玩笑不谈,这正是 H.264 所要做的。H.264 将图像分割成宏块–通常是 16×16 像素块,用于运动估计。它编码一个静态图像–通常称为 I 帧(内帧)。这是一个完整的帧,包含构建该帧所需的所有比特。随后的帧要么是 P 帧(预测帧),要么是 B 帧(双向预测帧)。P 帧是对上一帧中每个宏块的运动矢量进行编码的帧。因此,解码器必须根据之前的帧来构建 P 帧。解码器从视频流中的最后一个 I 帧开始,然后逐帧进行解码,在解码过程中将运动矢量递减相加,直到解码到当前帧。
B 帧更加有趣,它是双向预测,既预测过去的帧,也预测未来的帧。因此,你现在可以想象为什么苹果公司主页视频的压缩效果如此之好了。因为它实际上只是三个 I 帧,在这三个 I 帧中,宏块被左右平移。
假设你正在播放 YouTube 上的一段视频。你错过了最后几秒钟的对话,所以你往回刷了几秒钟。你是否注意到,它并没有立即从你刚刚选择的时间码开始播放。它会暂停片刻,然后再播放。因为你刚刚播放过,它已经从网络上缓冲了这些帧,为什么还要暂停?
是啊,这让我很不爽。为什么会这样?
因为你要求解码器跳转到某个任意帧,解码器必须重新进行所有计算–从最近的 I 帧开始,将运动矢量三角相加到你所在的帧–而这需要耗费大量计算,因此才会出现短暂的暂停。希望你现在不会那么烦恼了,因为你知道它实际上是在做艰苦的工作,而不是坐在那里让你烦恼。
由于只对运动矢量三角进行编码,因此这种技术对于任何有运动的视频来说都非常节省空间,但需要付出一定的计算代价。
现在,我们已经涵盖了空间压缩和时间压缩!到目前为止,我们已经通过量化节省了大量空间。色度子采样进一步将所需空间减半。此外,我们还进行了运动补偿,在视频中的约 300 个帧中只存储了 3 个实际帧。
在我看来,这很不错。现在怎么办?
现在我们来收尾和收尾。我们使用传统的无损熵编码器。为什么不呢?为了保险起见,我们还是把它放上去吧。
熵编码器
经过有损处理后的 I 帧包含冗余信息。P 帧和 B 帧中每个宏块的运动矢量–有整组的运动矢量具有相同的值–因为在我们的测试视频中,当图像平移时,几个宏块的移动量相同。
熵编码器将处理这种冗余。由于它是一种通用的无损编码器,我们不必担心它会做出什么取舍。我们可以恢复输入的所有数据。
然后,我们就大功告成了!这就是 H.264 等视频压缩编解码器的工作原理。这些就是它的技巧。
好极了!但我很想知道我们的车现在有多重。
原始视频的分辨率为 1232×1154。如果我们在这里进行计算,我们可以得到
5 秒 @ 60 fps = 1232x1154x60x3x5 => 1.2 GB
压缩视频 => 175 KB
如果我们对 3000 磅的汽车应用相同的比率,最终重量为 0.4 磅。6.5盎司!
是啊,真是神奇!
很明显,我将这一领域数十年的深入研究过于简单化了。如果你想了解更多,维基百科页面上有很多描述。
[^1]SSD Benchmarks
[^2]Nyquist-Shannon Sampling Theorem
[^3][Quantization](https://en.wikipedia.org/wiki/Quantization_(signal_processing)
本文文字及图片出自 H.264 is Magic











{kind=link}
共有 1 条讨论